
Pseudonimiseren, wat is dat?
- 4 december 2020
Scamander gelooft in de waarde van data. Daarom bevrijden we data en zetten die om in waarde. Waarde die bijdraagt aan het welzijn van onze klanten en medewerkers. Op een goede en ethische manier omgaan met data vinden we daarom van levensbelang. En nog eens extra als die data te maken heeft met personen en persoonsgegevens. Voor ons een reden om een blogserie te schrijven over pseudonomiseren. In deze eerste blog delen we met je wat pseudonimiseren eigenlijk is en hoe het werkt.
Definitie pseudonimiseren
Met pseudonimiseren voorkom je dat iemands identiteit bekend wordt bij personen die dit niet hoeven of mogen weten. Het is extra veiligheid waarmee je gegevens over individuen beschermt in het geval van een datalek.
De AVG definieert het als volgt (in artikel 4, lid 5): “Pseudonimiseren is het verwerken van persoonsgegevens op zodanige wijze dat de persoonsgegevens niet meer aan een specifieke betrokkene kunnen worden gekoppeld zonder dat er aanvullende gegevens worden gebruikt, mits deze aanvullende gegevens apart worden bewaard en technische en organisatorische maatregelen worden genomen om ervoor te zorgen dat de persoonsgegevens niet aan een geïdentificeerde of identificeerbare natuurlijke persoon worden gekoppeld.”
Kort gezegd is pseudonimiseren het vervangen van persoonskenmerken door een minder zeggende, maar unieke, code waardoor het niet meer mogelijk is de persoon direct te herleiden. Door het pseudonimiseren is het echter nog wel mogelijk om de gegevens te verreiken met andere bronnen die op dezelfde manier zijn gepseudonimiseerd.
Een voorbeeld:

Hoe werkt pseudonimiseren?
Tijdens het pseudonimiseren wordt er een algoritme gebruikt dat de direct identificerende persoonskenmerken vervangt door een versleutelde waarde. De sleutel die door dit algoritme wordt gebruikt, dient zeer zorgvuldig te worden bewaard. Hierbij is ook van groot belang dat de toegang tot deze sleutel zeer beperkt is.
Om er zeker van te zijn dat het niet mogelijk is om de pseudonimisering door een partij ongedaan te laten maken, is het daarnaast best-practice dat geen enkele partij betrokken bij de pseudonimisering beschikt over zowel de originele waarde als de uiteindelijk gepseudonimiseerde waarde. Om dit te bereiken is het vaak wenselijk om de pseudonimisering in twee stappen te laten verlopen.
Schematisch weergegeven:
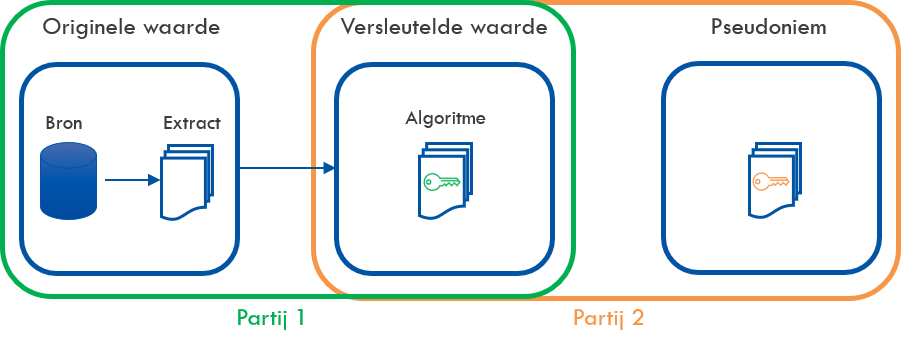
Partij 1 versleutelt de originele waarde in een versleutelde waarde. Vervolgens wordt deze versleutelde waarde naar een andere partij gestuurd. Deze tweede partij versleutelt de gegevens nogmaals (met een andere sleutel) om het uiteindelijke pseudoniem te produceren.
Doordat niemand in een dergelijke keten beschikt over de originele waarde en het uiteindelijke pseudoniem of over beide sleutels, is het niet mogelijk om de pseudonimisering ongedaan te maken. De scheiding tussen de partijen die de versleuteling verzorgen en het beheer van de sleutels vormt het fundament van de veiligheid die deze vorm van pseudonimiseren biedt.
Wat is het verschil met anonimiseren?
Bij anonimiseren worden de gegevens ontdaan van alle herleidbare persoonsgegevens. Na het anonimiseren van gegevens is er daardoor niet langer sprake van persoonsgegevens zoals deze in de AVG worden bedoeld. Dat betekent ook dat het niet mogelijk is om geanonimiseerde gegevens te verrijken met andere gegevens.
Vanwege de grote hoeveelheid en diversiteit aan gegevens die tegenwoordig beschikbaar is, is het lastig om te spreken van anonimiseren op het moment dat gegevens nog altijd over één individu gaan. De kans is namelijk groot dat er voldoende kenmerken aanwezig zijn om het onbedoeld toch mogelijk te maken andere gegevens te gebruiken om het proces ongedaan te maken. De enige manier om dit te voorkomen is het aggregeren van gegevens. Dan kunnen we met zekerheid over anonieme gegevens spreken omdat de gegevens dan niet langer over individuen gaan, maar over voldoende grote groepen (denk hierbij aan groepen van 10) van individuen. Daardoor zijn de gegevens niet langer herleidbaar tot een individu en zijn het niet langer persoonsgegevens.
Een voorbeeld:

Het essentiële verschil tussen anonimiseren en pseudonimiseren is dus dat anonimiseren een onomkeerbaar proces is en pseudonimiseren in theorie een omkeerbaar proces. Met de in deze blog omschreven maatregelen zorg je er echter voor dat ook bij pseudonimeren niet-geautoriseerde personen de oorspronkelijke persoonsgegevens niet kunnen inzien.
De volgende blog
In de volgende blog zullen we ingaan op het waarom van pseudonimiseren. In welke situaties is het nodig? Wat zijn de overwegingen om het toe te passen? En wanneer doe je dat juist niet? Klik hier om deze volgende blog te lezen.
Bas Rekveldt , Data Analist
Roxanne Robijns, Project Manager
Deel dit met uw volgers
Scamander gelooft in de waarde van data. Daarom bevrijden we data en zetten die om in waarde. Waarde die bijdraagt aan het welzijn van onze klanten en medewerkers. Op een goede en ethische manier omgaan met data vinden we daarom van levensbelang. En nog eens extra als die data te maken heeft met personen en persoonsgegevens. Voor ons een reden om een blogserie te schrijven over pseudonomiseren. In deze eerste blog delen we met je wat pseudonimiseren eigenlijk is en hoe het werkt.
Definitie pseudonimiseren
Met pseudonimiseren voorkom je dat iemands identiteit bekend wordt bij personen die dit niet hoeven of mogen weten. Het is extra veiligheid waarmee je gegevens over individuen beschermt in het geval van een datalek.
De AVG definieert het als volgt (in artikel 4, lid 5): “Pseudonimiseren is het verwerken van persoonsgegevens op zodanige wijze dat de persoonsgegevens niet meer aan een specifieke betrokkene kunnen worden gekoppeld zonder dat er aanvullende gegevens worden gebruikt, mits deze aanvullende gegevens apart worden bewaard en technische en organisatorische maatregelen worden genomen om ervoor te zorgen dat de persoonsgegevens niet aan een geïdentificeerde of identificeerbare natuurlijke persoon worden gekoppeld.”
Kort gezegd is pseudonimiseren het vervangen van persoonskenmerken door een minder zeggende, maar unieke, code waardoor het niet meer mogelijk is de persoon direct te herleiden. Door het pseudonimiseren is het echter nog wel mogelijk om de gegevens te verreiken met andere bronnen die op dezelfde manier zijn gepseudonimiseerd.
Een voorbeeld:
Hoe werkt pseudonimiseren?
Tijdens het pseudonimiseren wordt er een algoritme gebruikt dat de direct identificerende persoonskenmerken vervangt door een versleutelde waarde. De sleutel die door dit algoritme wordt gebruikt, dient zeer zorgvuldig te worden bewaard. Hierbij is ook van groot belang dat de toegang tot deze sleutel zeer beperkt is.
Om er zeker van te zijn dat het niet mogelijk is om de pseudonimisering door een partij ongedaan te laten maken, is het daarnaast best-practice dat geen enkele partij betrokken bij de pseudonimisering beschikt over zowel de originele waarde als de uiteindelijk gepseudonimiseerde waarde. Om dit te bereiken is het vaak wenselijk om de pseudonimisering in twee stappen te laten verlopen.
Schematisch weergegeven:
Partij 1 versleutelt de originele waarde in een versleutelde waarde. Vervolgens wordt deze versleutelde waarde naar een andere partij gestuurd. Deze tweede partij versleutelt de gegevens nogmaals (met een andere sleutel) om het uiteindelijke pseudoniem te produceren.
Doordat niemand in een dergelijke keten beschikt over de originele waarde en het uiteindelijke pseudoniem of over beide sleutels, is het niet mogelijk om de pseudonimisering ongedaan te maken. De scheiding tussen de partijen die de versleuteling verzorgen en het beheer van de sleutels vormt het fundament van de veiligheid die deze vorm van pseudonimiseren biedt.
Wat is het verschil met anonimiseren?
Bij anonimiseren worden de gegevens ontdaan van alle herleidbare persoonsgegevens. Na het anonimiseren van gegevens is er daardoor niet langer sprake van persoonsgegevens zoals deze in de AVG worden bedoeld. Dat betekent ook dat het niet mogelijk is om geanonimiseerde gegevens te verrijken met andere gegevens.
Vanwege de grote hoeveelheid en diversiteit aan gegevens die tegenwoordig beschikbaar is, is het lastig om te spreken van anonimiseren op het moment dat gegevens nog altijd over één individu gaan. De kans is namelijk groot dat er voldoende kenmerken aanwezig zijn om het onbedoeld toch mogelijk te maken andere gegevens te gebruiken om het proces ongedaan te maken. De enige manier om dit te voorkomen is het aggregeren van gegevens. Dan kunnen we met zekerheid over anonieme gegevens spreken omdat de gegevens dan niet langer over individuen gaan, maar over voldoende grote groepen (denk hierbij aan groepen van 10) van individuen. Daardoor zijn de gegevens niet langer herleidbaar tot een individu en zijn het niet langer persoonsgegevens.
Een voorbeeld:
Het essentiële verschil tussen anonimiseren en pseudonimiseren is dus dat anonimiseren een onomkeerbaar proces is en pseudonimiseren in theorie een omkeerbaar proces. Met de in deze blog omschreven maatregelen zorg je er echter voor dat ook bij pseudonimeren niet-geautoriseerde personen de oorspronkelijke persoonsgegevens niet kunnen inzien.
De volgende blog
In de volgende blog zullen we ingaan op het waarom van pseudonimiseren. In welke situaties is het nodig? Wat zijn de overwegingen om het toe te passen? En wanneer doe je dat juist niet? Klik hier om deze volgende blog te lezen.
Bas Rekveldt , Data Analist
Roxanne Robijns, Project Manager







")
















Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Copyright Scamander 2024
Copyright Scamander 2024