
Pseudonimiseren, waarom?
- 8 december 2020
Vorige week publiceerden we de eerste blog van onze blogserie over pseudonimiseren. In die blog leggen we uit wat pseudonomiseren is en hoe het werkt. In deze tweede blog gaan we in op het ‘waarom’ van pseudonimiseren. Wanneer gebruik je het wel en wanneer gebruik je het niet? Maar ook, wanneer is het niet noodzakelijk, maar toch wel verstandig om het toe te passen?
Waarom pseudonimiseren?
Pseudonimiseren is een krachtige maatregel die je inzet om persoonsgegevens te beschermen. Door het pseudonimiseren van gegevens wordt het moeilijker gemaakt om de gegevens te herleiden (direct of indirect) naar een individu. Het zorgt ervoor dat de impact bij ongeoorloofd gebruik of openbaring van de persoonsgegevens wordt verkleind terwijl de persoonsgegevens wel verwerkt kunnen worden.
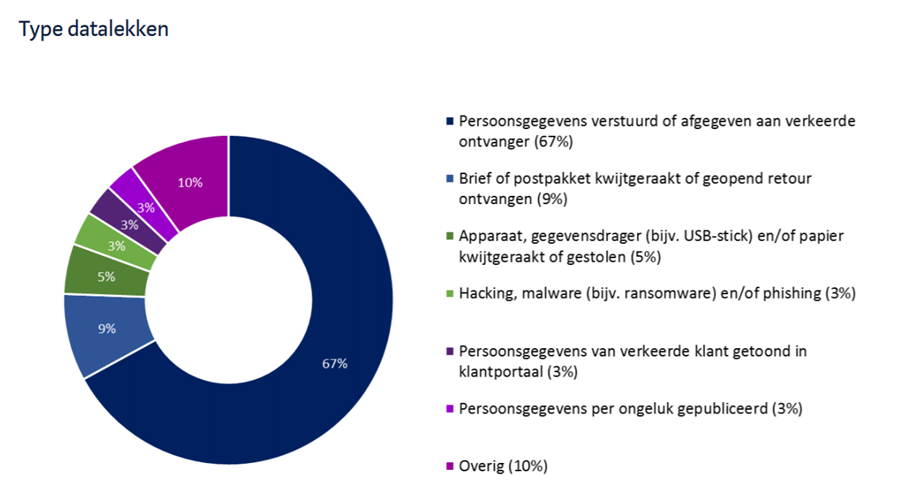
Dat het nodig is om persoonsgegevens te beschermen, blijkt wel uit gegevens van de Autoriteit Persoonsgegevens. Het aantal datalekmeldingen is sinds 2016 enorm toegenomen. In 2019 ging het in 67% van de gevallen om persoonsgegevens die zijn verstuurd of afgegeven aan een verkeerde ontvanger. Zie onderstaande afbeeldingen uit Jaarrapportage meldplicht datalekken 2019.

Wanneer is pseudonimiseren nodig?
Wanneer het gebruik van persoonsgegevens noodzakelijk is om het doel van de verwerking te bereiken is het wenselijk om deze te pseudonimiseren. Bijvoorbeeld om voor gemeenten inzichtelijk te maken welke gezinnen gebruik maken van meerdere voorzieningen. Wel is het zo dat ook wanneer je persoonsgegevens pseudonimiseert, de grondslag van deze verwerking (AVG, artikel 6) vastgesteld dient te worden om het rechtmatig te maken. Dit kan het beste in overleg met de Privacy Officer of Functionaris Gegevensbescherming worden vastgesteld.
Wanneer niet pseudonimiseren?
Wanneer het ook noodzakelijk is om de resultaten van de verwerking te herleiden tot een individu is het pseudonimiseren van de persoonsgegevens niet wenselijk. Bijvoorbeeld in het geval van handhaving of fraudebestrijding. Deze noodzaak dient dan wel onderbouwd te worden en er zal meer aandacht besteedt moeten worden aan andere maatregelen om de persoonsgegevens te beschermen.
Wanneer is het toch verstandig?
Wanneer er geen persoonsgegevens worden verwerkt, hoef je geen pseudonimisering toe te passen. In sommige gevallen is het echter toch het overwegen waard, als is het maar uit zorgvuldigheid. Denk hierbij aan gevallen waarbij er bedrijfsgegevens of dossiernummers worden gebruikt of verwerkt. Wanneer het daarbij niet direct noodzakelijk is om de resultaten van de verwerking te herleiden tot deze brongegevens, is het wel zo netjes om ze met pseudonimisering te beschermen.
De volgende blog
In de volgende blog gaan we in op het zelf uitvoeren van pseudonimiseren. Wat zijn de voordelen hiervan? En wat zijn de nadelen? Deze volgende blog lees je hier.
Bas Rekveldt , Data Analist
Roxanne Robijns, Project Manager
Deel dit met uw volgers
Vorige week publiceerden we de eerste blog van onze blogserie over pseudonimiseren. In die blog leggen we uit wat pseudonomiseren is en hoe het werkt. In deze tweede blog gaan we in op het ‘waarom’ van pseudonimiseren. Wanneer gebruik je het wel en wanneer gebruik je het niet? Maar ook, wanneer is het niet noodzakelijk, maar toch wel verstandig om het toe te passen?
Waarom pseudonimiseren?
Pseudonimiseren is een krachtige maatregel die je inzet om persoonsgegevens te beschermen. Door het pseudonimiseren van gegevens wordt het moeilijker gemaakt om de gegevens te herleiden (direct of indirect) naar een individu. Het zorgt ervoor dat de impact bij ongeoorloofd gebruik of openbaring van de persoonsgegevens wordt verkleind terwijl de persoonsgegevens wel verwerkt kunnen worden.
Dat het nodig is om persoonsgegevens te beschermen, blijkt wel uit gegevens van de Autoriteit Persoonsgegevens. Het aantal datalekmeldingen is sinds 2016 enorm toegenomen. In 2019 ging het in 67% van de gevallen om persoonsgegevens die zijn verstuurd of afgegeven aan een verkeerde ontvanger. Zie onderstaande afbeeldingen uit Jaarrapportage meldplicht datalekken 2019.
Wanneer is pseudonimiseren nodig?
Wanneer het gebruik van persoonsgegevens noodzakelijk is om het doel van de verwerking te bereiken is het wenselijk om deze te pseudonimiseren. Bijvoorbeeld om voor gemeenten inzichtelijk te maken welke gezinnen gebruik maken van meerdere voorzieningen. Wel is het zo dat ook wanneer je persoonsgegevens pseudonimiseert, de grondslag van deze verwerking (AVG, artikel 6) vastgesteld dient te worden om het rechtmatig te maken. Dit kan het beste in overleg met de Privacy Officer of Functionaris Gegevensbescherming worden vastgesteld.
Wanneer niet pseudonimiseren?
Wanneer het ook noodzakelijk is om de resultaten van de verwerking te herleiden tot een individu is het pseudonimiseren van de persoonsgegevens niet wenselijk. Bijvoorbeeld in het geval van handhaving of fraudebestrijding. Deze noodzaak dient dan wel onderbouwd te worden en er zal meer aandacht besteedt moeten worden aan andere maatregelen om de persoonsgegevens te beschermen.
Wanneer is het toch verstandig?
Wanneer er geen persoonsgegevens worden verwerkt, hoef je geen pseudonimisering toe te passen. In sommige gevallen is het echter toch het overwegen waard, als is het maar uit zorgvuldigheid. Denk hierbij aan gevallen waarbij er bedrijfsgegevens of dossiernummers worden gebruikt of verwerkt. Wanneer het daarbij niet direct noodzakelijk is om de resultaten van de verwerking te herleiden tot deze brongegevens, is het wel zo netjes om ze met pseudonimisering te beschermen.
De volgende blog
In de volgende blog gaan we in op het zelf uitvoeren van pseudonimiseren. Wat zijn de voordelen hiervan? En wat zijn de nadelen? Deze volgende blog lees je hier.
Bas Rekveldt , Data Analist
Roxanne Robijns, Project Manager







")
















Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Copyright Scamander 2024
Copyright Scamander 2024