
Expert meets Expert Analytics – van BI naar BA
- 14 maart 2019
Op 22 mei 2019 verzamelde zich bij Scamander een groep BI-experts, nieuwsgierig naar de wondere wereld van Business Analytics. Ze kwamen voor de Expert meets Expert Analytics sessie ‘van BI naar BA’. Tijdens deze sessie leerden ze niet alleen meer over de theorie en de mogelijkheden van voorspelmodellen en ‘advanced analytics’, ze gingen ook zelf aan de slag in Python of R met het voorspellen van huizenprijzen. Een concrete voorbeeldcase van Gemeente Rotterdam over het herkennen van risicowegen en het reduceren van risico zorgde daarbij voor extra inspiratie.

Gemeente Rotterdam – casus Mobiliteit
Na een korte introductie over het vakgebied Business Analytics door Roxanne Robijns, Consultant Business Analytics bij Scamander, trapte Sjoerd Braaksma de sessie af met een inspiratiesessie over de casus Mobiliteit “Risicowegen herkennen en risico reduceren”. Als Data Scientist bij Gemeente Rotterdam heeft hij deze casus met collega’s opgezet en uitgevoerd. Sjoerd vertelde de deelnemers eerst meer over het doel van Data Science, de werkzaamheden die je als Data Scientist uitvoert en hoe voorspelmodellen werken. Daarna ging hij in op de aanpak die is gehanteerd bij de casus mobiliteit en deelde hij welke uitdagingen ze bij de uitvoer zijn tegengekomen.
Voorspelmodellen
Roxanne Robijns nam het presenteerstokje over van Sjoerd om de deelnemers klaar te stomen voor de eerste eigen programmeerstapjes met een spoedcursus Modeling. Dit is een onderdeel uit CRISP-DM, ofwel de Data Science Project Life Cycle. Zo leerden deelnemers onder meer de type vraagstukken Regression, Classification en Clustering te herkennen en hoe je Overfitting en Underfitting van je model kunt voorkomen. Daarnaast werd op een toegankelijke manier enkele modelleeralgoritmen uitgelegd, zoals Linear regression, Linear classifier, SVM, Random Forest en K-nearest neighbour. Duidelijk was, dat het evalueren van je modellen zo simpel nog niet is. Na deze spoedcursus konden de deelnemers zich verdiend te goed doen aan lekkere broodjes en drankjes.
Zelf aan de slag
Na een keuze voor gebruik van Python of R, werd er in vier stappen toegewerkt naar een voorspellingsmodel voor de verkoopprijs van een huis. Elke stap werd duidelijk toegelicht door collega Bas Rekveldt, inclusief een aantal voorbeelden.

Stap 1 – Initial Exploration: Correlation and Visualization
In deze eerste stap werd een dataset onderzocht die verschillende eigenschappen van huizen bevatte, waaronder het perceeloppervlak en het aantal garages. Enkele statistieken over de dataset werden onderzocht. Denk aan gemiddelden, standaarddeviaties en mogelijke correlaties tussen een eigenschap en de verkoopprijs.
Stap 2 – Digging Deeper: Missing Data and Outlier Detection
De volgende stap werd genomen door te onderzoeken of er waarden misten in de gebruikte dataset; de welbekende NULL-values in SQL. Daar moesten we nog iets mee, anders zou het de voorspelmodellen flink kunnen beïnvloeden. Hetzelfde geldt voor de ‘outliers’ in de data, deze kunnen duiden op bijvoorbeeld typefouten of op andere manieren vervuilde data (een datakwaliteit issue…).
Stap 3 – Towards Testing: Data Transformation and Feature Derivation
In stap 3 werd er aandacht besteed aan de vier basisaannames van een regressie-analyse: Normality, Homescedasticity, Linearity en Absence of correlated errors. Deze kennis is nodig om te kunnen beoordelen welke statistische methode het beste kan, en überhaupt mag, worden toegepast op de onderzoeksvraag waar je mee bezig bent.
Stap 4 – Putting it all Together: Training a Regression Model
Tijdens de laatste stap van de sessie werd het OLS (Ordinary Least Squares) Regression model getraind om huizenprijzen te voorspellen. Om een beetje competitie in te bouwen, werden de gecreëerde modellen vervolgens beoordeeld met de R²-score. De casus startte met een waarde van 0.77. Niet slecht, maar nog voldoende ruimte voor verbetering. Een deelnemer wist het model zelfs zo aan te passen dat er een waarde van 0.85 werd verkregen!
Evaluatie
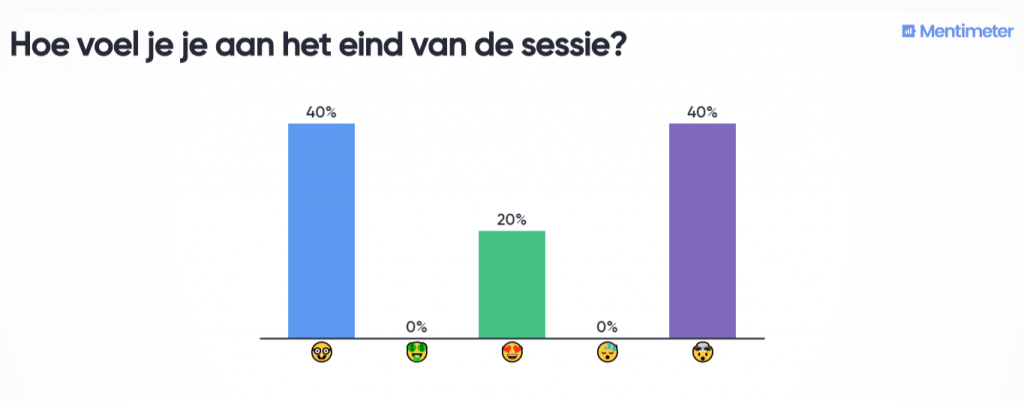
De sessie werd afgesloten met een evaluatie van de geboden kennis en gemaakte opdrachten. De deelnemers hebben ook een aantal mogelijke onderzoeksvragen geformuleerd. Voorbeelden zijn: Hoeveel studenten zullen zich in 2023 inschrijven voor het nieuwe studiejaar? Hoe kunnen we onze klanten behouden? En wat wordt de groei of afname van het aantal inwoners in een stad of stadsgebied? Het was goed om te merken dat de meeste deelnemers zich na deelname aan de Expert meets Expert Analytics ‘slim’ voelden en blij waren met de opgedane kennis, met hier en daar wat ‘stoom uit de oren’ door de hoeveelheid informatie. Het was zeker geslaagde eerste kennismaking met Business Analytics.
Ook nieuwsgierig?
Was je er niet bij op 22 mei en heb je wel interesse in een dergelijke workshop? Roxanne Robijns en Max Prinz vertellen je er graag meer over. Neem contact met ons op voor de mogelijkheden via 030 – 602 9000 of lverhoeven@scamander.com.
Deel dit met uw volgers
Comments are closed.
Op 22 mei 2019 verzamelde zich bij Scamander een groep BI-experts, nieuwsgierig naar de wondere wereld van Business Analytics. Ze kwamen voor de Expert meets Expert Analytics sessie ‘van BI naar BA’. Tijdens deze sessie leerden ze niet alleen meer over de theorie en de mogelijkheden van voorspelmodellen en ‘advanced analytics’, ze gingen ook zelf aan de slag in Python of R met het voorspellen van huizenprijzen. Een concrete voorbeeldcase van Gemeente Rotterdam over het herkennen van risicowegen en het reduceren van risico zorgde daarbij voor extra inspiratie.
Gemeente Rotterdam – casus Mobiliteit
Na een korte introductie over het vakgebied Business Analytics door Roxanne Robijns, Consultant Business Analytics bij Scamander, trapte Sjoerd Braaksma de sessie af met een inspiratiesessie over de casus Mobiliteit “Risicowegen herkennen en risico reduceren”. Als Data Scientist bij Gemeente Rotterdam heeft hij deze casus met collega’s opgezet en uitgevoerd. Sjoerd vertelde de deelnemers eerst meer over het doel van Data Science, de werkzaamheden die je als Data Scientist uitvoert en hoe voorspelmodellen werken. Daarna ging hij in op de aanpak die is gehanteerd bij de casus mobiliteit en deelde hij welke uitdagingen ze bij de uitvoer zijn tegengekomen.
Voorspelmodellen
Roxanne Robijns nam het presenteerstokje over van Sjoerd om de deelnemers klaar te stomen voor de eerste eigen programmeerstapjes met een spoedcursus Modeling. Dit is een onderdeel uit CRISP-DM, ofwel de Data Science Project Life Cycle. Zo leerden deelnemers onder meer de type vraagstukken Regression, Classification en Clustering te herkennen en hoe je Overfitting en Underfitting van je model kunt voorkomen. Daarnaast werd op een toegankelijke manier enkele modelleeralgoritmen uitgelegd, zoals Linear regression, Linear classifier, SVM, Random Forest en K-nearest neighbour. Duidelijk was, dat het evalueren van je modellen zo simpel nog niet is. Na deze spoedcursus konden de deelnemers zich verdiend te goed doen aan lekkere broodjes en drankjes.
Zelf aan de slag
Na een keuze voor gebruik van Python of R, werd er in vier stappen toegewerkt naar een voorspellingsmodel voor de verkoopprijs van een huis. Elke stap werd duidelijk toegelicht door collega Bas Rekveldt, inclusief een aantal voorbeelden.
Stap 1 – Initial Exploration: Correlation and Visualization
In deze eerste stap werd een dataset onderzocht die verschillende eigenschappen van huizen bevatte, waaronder het perceeloppervlak en het aantal garages. Enkele statistieken over de dataset werden onderzocht. Denk aan gemiddelden, standaarddeviaties en mogelijke correlaties tussen een eigenschap en de verkoopprijs.
Stap 2 – Digging Deeper: Missing Data and Outlier Detection
De volgende stap werd genomen door te onderzoeken of er waarden misten in de gebruikte dataset; de welbekende NULL-values in SQL. Daar moesten we nog iets mee, anders zou het de voorspelmodellen flink kunnen beïnvloeden. Hetzelfde geldt voor de ‘outliers’ in de data, deze kunnen duiden op bijvoorbeeld typefouten of op andere manieren vervuilde data (een datakwaliteit issue…).
Stap 3 – Towards Testing: Data Transformation and Feature Derivation
In stap 3 werd er aandacht besteed aan de vier basisaannames van een regressie-analyse: Normality, Homescedasticity, Linearity en Absence of correlated errors. Deze kennis is nodig om te kunnen beoordelen welke statistische methode het beste kan, en überhaupt mag, worden toegepast op de onderzoeksvraag waar je mee bezig bent.
Stap 4 – Putting it all Together: Training a Regression Model
Tijdens de laatste stap van de sessie werd het OLS (Ordinary Least Squares) Regression model getraind om huizenprijzen te voorspellen. Om een beetje competitie in te bouwen, werden de gecreëerde modellen vervolgens beoordeeld met de R²-score. De casus startte met een waarde van 0.77. Niet slecht, maar nog voldoende ruimte voor verbetering. Een deelnemer wist het model zelfs zo aan te passen dat er een waarde van 0.85 werd verkregen!
Evaluatie
De sessie werd afgesloten met een evaluatie van de geboden kennis en gemaakte opdrachten. De deelnemers hebben ook een aantal mogelijke onderzoeksvragen geformuleerd. Voorbeelden zijn: Hoeveel studenten zullen zich in 2023 inschrijven voor het nieuwe studiejaar? Hoe kunnen we onze klanten behouden? En wat wordt de groei of afname van het aantal inwoners in een stad of stadsgebied? Het was goed om te merken dat de meeste deelnemers zich na deelname aan de Expert meets Expert Analytics ‘slim’ voelden en blij waren met de opgedane kennis, met hier en daar wat ‘stoom uit de oren’ door de hoeveelheid informatie. Het was zeker geslaagde eerste kennismaking met Business Analytics.
Ook nieuwsgierig?
Was je er niet bij op 22 mei en heb je wel interesse in een dergelijke workshop? Roxanne Robijns en Max Prinz vertellen je er graag meer over. Neem contact met ons op voor de mogelijkheden via 030 – 602 9000 of lverhoeven@scamander.com.
-
Erik van Opmeer
- 8 april 2019
Ben benieuwd
Comments are closed.




")



















Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Copyright Scamander 2024
Copyright Scamander 2024
Ben benieuwd