
Expert meets Expert Data Quality
- 4 juli 2019
Het tastbaar maken van de impact van het verwaarlozen van datakwaliteit voor organisaties is een uitdaging. Het doel van deze Expert meets Expert sessie was het aanreiken van (best)-practices door het uitwisselen van ervaringen en eigen inzichten.
Om 15.00 uur trapte Ronald Kok, Senior Data Governance consultant én medeoprichter van Scamander, de goedbezochte Expert meets Expert sessie af met een bevinding:
‘Datakwaliteit is vaak een lastig onderwerp. De meeste bestuurders snappen best dat het belangrijk is, maar zodra hier daadwerkelijk geld en tijd in geïnvesteerd moet worden, vragen ze zich af of dat wel echt nodig is. Én wie hier dan verantwoordelijk voor is.’
Vervolgens werden er twee vragen aan de deelnemers gesteld, als voorbereiding op de presentaties van de twee sprekers van de sessie. Ook werd ze gevraagd om alle DO’s en DON’ts die ze willen delen of die ze oppikken tijdens de sessies, op geeltjes te schrijven en die te verzamelen op het aanwezige whiteboard. (zie het resultaat aan het einde van dit artikel)
Vraag 1:
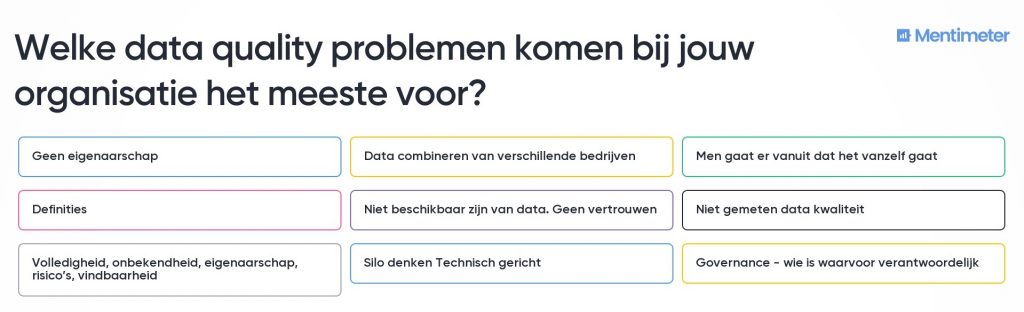


Vraag 2:
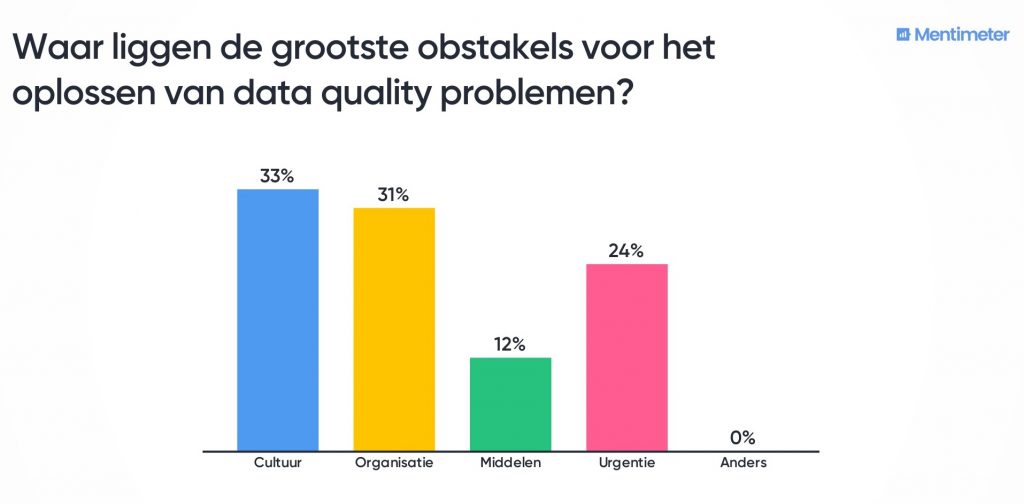
Datakwaliteit in de praktijk bij KPN
Omdat Olaf Slomp, Head of Data Quality bij KPN, onverhoopt niet ‘live’ aanwezig kon zijn tijdens de sessie, presenteerde hij via een video. Op deze manier deelde Olaf drie verschillende cases. De belangrijkste les die hij de aanwezigen meegaf was:
- Er is helaas geen ‘One size fits all’ oplossing. Je kijkt per case wat het beste werkt. Belangrijk hierbij is:
- Benoem eigenaarschap – want zonder eigenaar is er geen voortgang.
- Zoek benefithouders – wie voelt de pijn van de slechte datakwaliteit? Wie gaat er voordeel halen wanneer dit wordt opgelost EN heeft deze persoon invloed daarop?
- Bepaal een slimme migratiestrategie – dit voorkomt onnodig werk.
De volgende DO’s verdienden volgens de deelnemers speciale aandacht:
- Eigenaar & benefithouders kunnen verschillende personen zijn.
- Start vanuit een goed informatiemodel en -architectuur.
- Maak aannemelijk wat de monetaire waarde is van datakwaliteit. Al wordt hierbij wel opgemerkt dat dit eenvoudiger is als het gaat om grote datasets.
Een praktijkverhaal over centraal georganiseerde Datakwaliteitsmonitoring bij Rijkswaterstaat
Kasper Kisjes, Senior Advisor Data Quality bij Rijkswaterstaat, nam vervolgens het woord en vertelde dat Rijkswaterstaat in 2016 een stevige ambitie neerzette: het bereiken van autoriteit op het gebied van datakwaliteit. Maar, legde Kasper uit, er waren nog wel wat uitdagingen. De belangrijkste zijn dat de data bij Rijkswaterstaat opgesloten is in silo’s per domein en proces en dat er nauwelijks eigenaarschap was van data, veelal omdat data werd gezien als een bijproduct van primaire processen. Met slechts een handjevol beschikbare mensen beschikbaar voor Data Management en zo’n 200 databases met elk een veelvoud aan tabellen en velden leek dit bijna een onmogelijke opgave.
Een veelgehoord advies is dat je al eerste je Governance op orde moet brengen. Dat is een hele logische, maar Kasper ondervond dat dit tijd kost en zie dan maar eens draagvlak te houden. Daarom is gekozen voor een aanpak waarbij meten centraal staat, met iteratieve verbeteringen en met een datakwaliteitsraamwerk als kapstok. Het bleek een traject van twee stappen vooruit en een stap terug. Maar de resultaten zijn er!
Terugkijkend op het datakwaliteitstraject tot nu toe, hanteerde Kasper een heel handig diagram waarin de inzichten en tips voor de deelnemers worden samengevat:
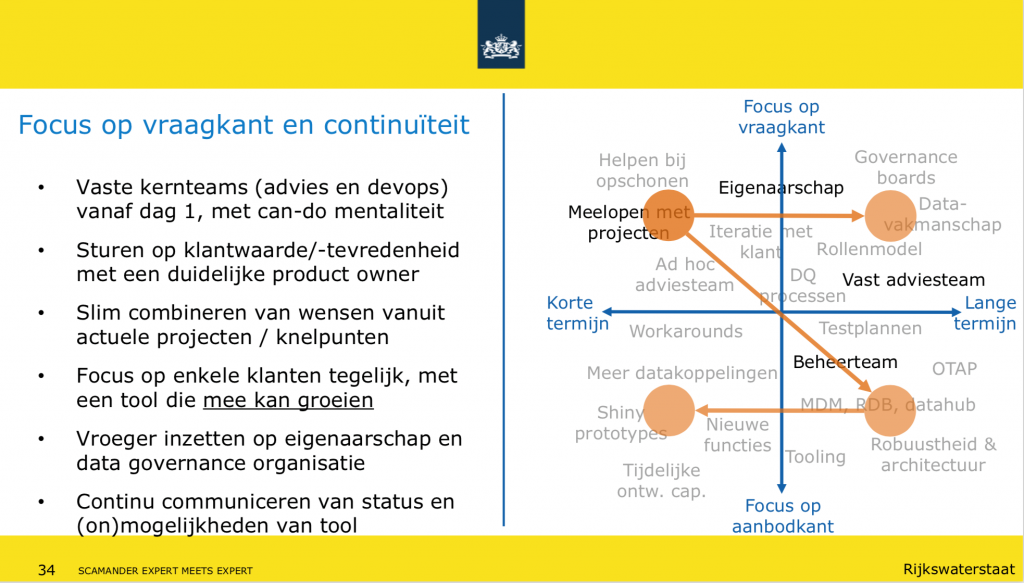
Discussie
Na een welverdiende pauze, begeleiden Scamander experts Richard Slingerland en Marcel de Roon een discussie door gebruik te maken van aantal stellingen waarop deelnemers hun mening konden geven en konden sparren met de aanwezige vakgenoten.
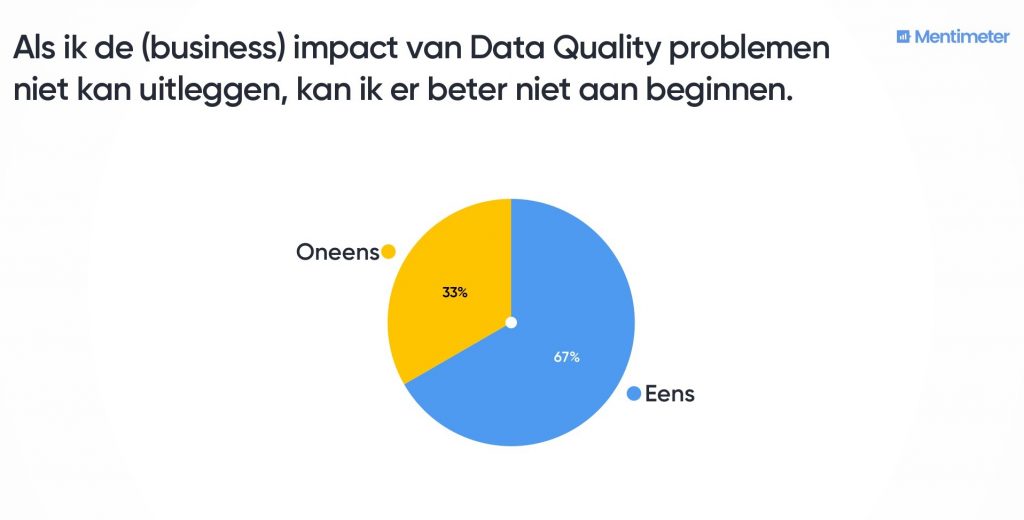
Waarom is slechts 67% het eens met deze stelling?
Dat was de meest gehoorde feedback uit het publiek. Je brengt de datakwaliteit toch op order voor de business? Dan moet je dit toch aan ze kunnen uitleggen? Het antwoord van degenen die het niet eens waren met deze stelling, was dat je vaak de impact nog niet zo goed kunt uitleggen wanneer je datakwaliteit gaat aanpakken. Kasper Kisjes vult hierbij aan: Je wilt dat mensen in je bedrijf dingen anders gaan doen ten behoeve van de datakwaliteit. Dan moet je ze inderdaad wel kunnen uitleggen waarom ze dat doen. Maar dat neemt niet weg dat het soms lastig is om uit te leggen wat nou precies de impact is, vooral uitgedrukt in kosten. Een mogelijke oplossing is de betrokkenen te vragen hoeveel tijd ze exact besteden aan het op orde krijgen van data. Een voorbeeld hiervan is de tijd die je nodig hebt om iets moeten uitzoeken omdat de gegevens waarmee je moet werken niet kloppen. Verloren tijd als indicator is ook heel overtuigend.
Andere suggesties die voorbij kwamen om draagvlak en urgentie te creëren zijn:
- Wanneer het bedrijf groeit, wil de business vaak investeren in beter of efficiënter laten verlopen van processen. Er geldt dan ook voor datakwaliteit.
- Een andere indicator die goed werkt is klant’on’tevredenheid. Als datakwaliteit dit gaat oplossingen, krijg je buy-in.
- Zet de pijnpunten flink aan, bijvoorbeeld op basis van het jaarverslag van de organisatie. Relateer datakwaliteit aan wat er niet goed gaat en je hebt automatisch een business case.
- Maak het persoonlijk, benadruk het persoonlijk gewin of de persoonlijke pijn.
- Een tip uit de Non-Invasive Data Governance hoek: laat mensen opnoemen wat ze allemaal NIET kunnen doen door slechte data. Door dit te benoemen krijg je vanzelf de vraag
- Verzamel shockerende cases rondom datakwaliteit met zaken die grote gevolgen hebben als ze niet worden ondervangen. Zo laat je zien wat er gebeurt als je niets doet.
- Maak transparant waar de data, die mensen bijvoorbeeld moeten invoeren in een applicatie, voor dienen en waarom je die nodig hebt.
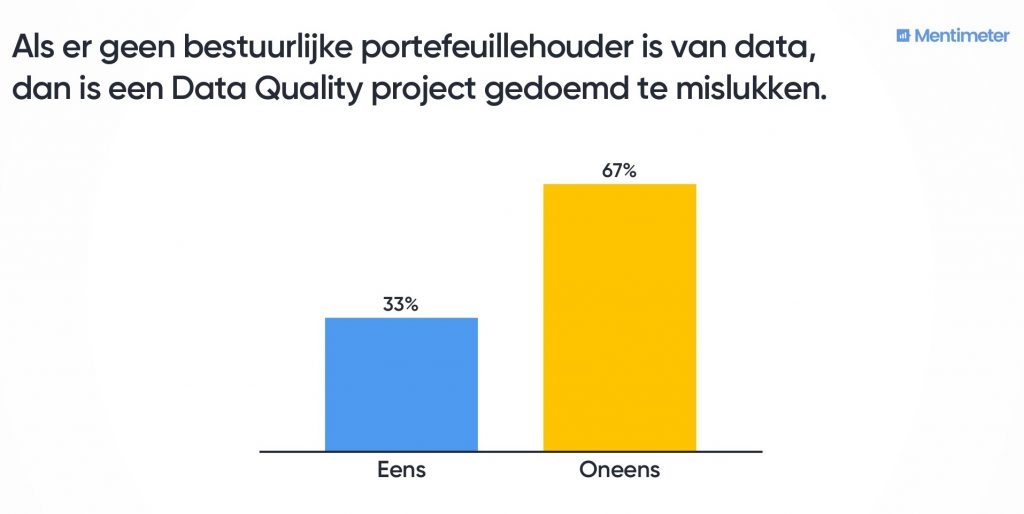
Slechts 33% geeft aan dat een bestuurlijke portefeuillehouder van data nodig is.
Opvallend, omdat er bij veel van de bedrijven van de aanwezigen toch in silo’s gewerkt wordt. Je hebt dan toch iemand nodig die over deze silo’s heen besluiten kan nemen? Steun van hogerhand is toch onontbeerlijk? Maar al snel wordt duidelijk in de discussie dat het hebben van benefithouders het meest belangrijk is. Dat zijn je pleitbezorgers en dat hoeven niet persé bestuurlijke portefeuillehouders te zijn. Kasper Kisjes vertelt dat ze bij Rijkswaterstaat zijn gestart met een team van enthousiastelingen die over de silo’s heen aan de slag konden. Ook wanneer je bottom-up aan de slag gaat, kun je ver komen. Belangrijk is wel dat je datakwaliteit niet als project ziet wat je opstart en ook weer afrondt. Datakwaliteit moet een structureel onderdeel worden van je organisatie. Je wilt tenslotte continu grip krijgen op datakwaliteit.
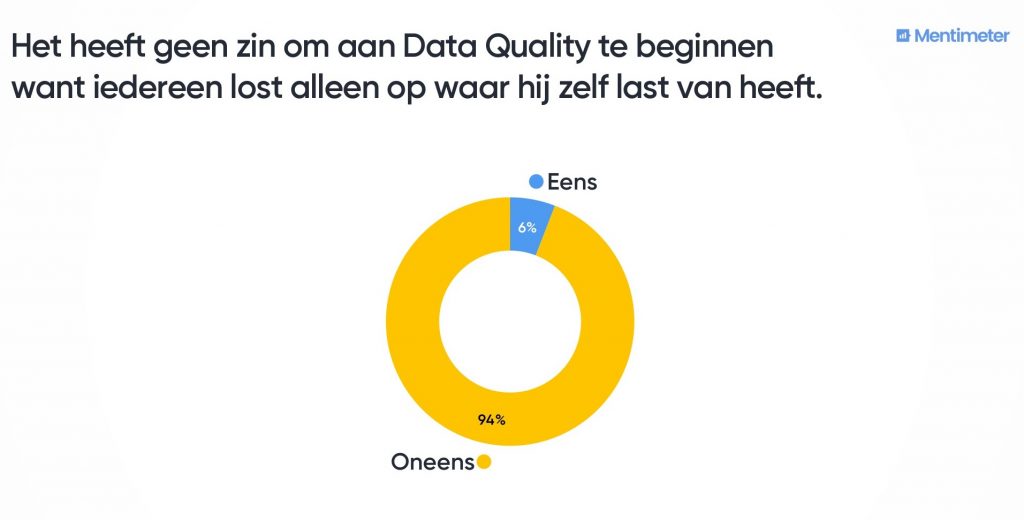
Data Quality geen verloren zaak…
Ondanks dat veel deelnemers herkennen dat het zeker voorkomt dat medewerkers zich alleen verantwoordelijk voelen voor ‘hun’ data, geloven ze toch dat het geen verloren zaak is. Ja, er moet wel centrale sturing zijn om te voorkomen dat er wordt gedacht in ‘mijn’ versus ‘zijn/haar’ data. De belangrijkste DO’s die voortkwamen uit dit discussiepunt, waren:
- Zorg voor transparantie: Het gemeenschappelijk belang van kwaliteit van data moet voor iedereen duidelijk zijn. Alleen dan krijg je mensen in beweging.
- Zorg dat je de verbinder bent tussen eigenaarschap en benefithouder. Wanneer je zorgt dat de belangen bij elkaar komen, krijg je de boel in beweging.

Toolselectie niet het juiste startpunt
De grote meerderheid was het erover eens dat het kiezen voor een datakwaliteitstool niet het juiste startpunt is voor het structureel aanpakken van datakwaliteit. Wel beaamde men de waarde van bijvoorbeeld een dashboard om inzichtelijk en vooral ook visueel te maken wat de issues zijn. Want gevoel en beleving zijn zeer belangrijk wanneer je mensen in beweging wilt krijgen. Kasper Kisjes geeft aan dat je eigenlijk moet starten met het in kaart brengen van issues. En deze issues zitten aan de vraagzijde. Zo krijg je duidelijk waar je het voor doet. Wanneer je de issues boven water hebt, kun je pas een goede toolselectie maken. Een goede tool heb je overigens wel nodig om het gehele datakwaliteitsproces te meten en monitoren. Alleen dan maak je datakwaliteit tot een structureel proces.
Wrap-up met DO’s en DON’Ts
Een groot gedeelte van de Data Quality problemen en obstakels die de deelnemers aan het begin van de sessie noemden, zijn in de presentaties en discussie geadresseerd. Daarbij zijn er door de deelnemers heel wat DO’s en DON’Ts gedeeld en opgehaald.

Afsluiting
Als afsluiting lichtte Ronald Kok nog toe dat niet alleen het succes maar ook de energie zit in de samenwerking. Wanneer je investeert in het bijeenbrengen van personen en belangen, dan heb je de eerste slag gewonnen. Een heel goed instrument daarvoor is het spel Datapoly. Dit is terloops ter sprake gekomen tijdens de diverse breaks.
Daarnaast gaf hij de tip dat de Self-Assessment Rijksoverheid een heel goed middel is om het bestuur mee te krijgen in het onderwerp, zo ook voor datakwaliteit. Het geeft duidelijk aan waar je staat op basis van IST en SOLL. Vaak kun je dan na een korte investering in tijd, ongeveer een kwartier om een Self-Assessment in te vullen, de discussie aanzwengelen. Wil je hier zelf mee aan de slag? Klik dan op deze link om het materiaal aan te vragen.
Deel dit met uw volgers
Comments are closed.
Het tastbaar maken van de impact van het verwaarlozen van datakwaliteit voor organisaties is een uitdaging. Het doel van deze Expert meets Expert sessie was het aanreiken van (best)-practices door het uitwisselen van ervaringen en eigen inzichten.
Om 15.00 uur trapte Ronald Kok, Senior Data Governance consultant én medeoprichter van Scamander, de goedbezochte Expert meets Expert sessie af met een bevinding:
‘Datakwaliteit is vaak een lastig onderwerp. De meeste bestuurders snappen best dat het belangrijk is, maar zodra hier daadwerkelijk geld en tijd in geïnvesteerd moet worden, vragen ze zich af of dat wel echt nodig is. Én wie hier dan verantwoordelijk voor is.’
Vervolgens werden er twee vragen aan de deelnemers gesteld, als voorbereiding op de presentaties van de twee sprekers van de sessie. Ook werd ze gevraagd om alle DO’s en DON’ts die ze willen delen of die ze oppikken tijdens de sessies, op geeltjes te schrijven en die te verzamelen op het aanwezige whiteboard. (zie het resultaat aan het einde van dit artikel)
Vraag 1:
Vraag 2:
Datakwaliteit in de praktijk bij KPN
Omdat Olaf Slomp, Head of Data Quality bij KPN, onverhoopt niet ‘live’ aanwezig kon zijn tijdens de sessie, presenteerde hij via een video. Op deze manier deelde Olaf drie verschillende cases. De belangrijkste les die hij de aanwezigen meegaf was:
- Er is helaas geen ‘One size fits all’ oplossing. Je kijkt per case wat het beste werkt. Belangrijk hierbij is:
- Benoem eigenaarschap – want zonder eigenaar is er geen voortgang.
- Zoek benefithouders – wie voelt de pijn van de slechte datakwaliteit? Wie gaat er voordeel halen wanneer dit wordt opgelost EN heeft deze persoon invloed daarop?
- Bepaal een slimme migratiestrategie – dit voorkomt onnodig werk.
De volgende DO’s verdienden volgens de deelnemers speciale aandacht:
- Eigenaar & benefithouders kunnen verschillende personen zijn.
- Start vanuit een goed informatiemodel en -architectuur.
- Maak aannemelijk wat de monetaire waarde is van datakwaliteit. Al wordt hierbij wel opgemerkt dat dit eenvoudiger is als het gaat om grote datasets.
Een praktijkverhaal over centraal georganiseerde Datakwaliteitsmonitoring bij Rijkswaterstaat
Kasper Kisjes, Senior Advisor Data Quality bij Rijkswaterstaat, nam vervolgens het woord en vertelde dat Rijkswaterstaat in 2016 een stevige ambitie neerzette: het bereiken van autoriteit op het gebied van datakwaliteit. Maar, legde Kasper uit, er waren nog wel wat uitdagingen. De belangrijkste zijn dat de data bij Rijkswaterstaat opgesloten is in silo’s per domein en proces en dat er nauwelijks eigenaarschap was van data, veelal omdat data werd gezien als een bijproduct van primaire processen. Met slechts een handjevol beschikbare mensen beschikbaar voor Data Management en zo’n 200 databases met elk een veelvoud aan tabellen en velden leek dit bijna een onmogelijke opgave.
Een veelgehoord advies is dat je al eerste je Governance op orde moet brengen. Dat is een hele logische, maar Kasper ondervond dat dit tijd kost en zie dan maar eens draagvlak te houden. Daarom is gekozen voor een aanpak waarbij meten centraal staat, met iteratieve verbeteringen en met een datakwaliteitsraamwerk als kapstok. Het bleek een traject van twee stappen vooruit en een stap terug. Maar de resultaten zijn er!
Terugkijkend op het datakwaliteitstraject tot nu toe, hanteerde Kasper een heel handig diagram waarin de inzichten en tips voor de deelnemers worden samengevat:
Discussie
Na een welverdiende pauze, begeleiden Scamander experts Richard Slingerland en Marcel de Roon een discussie door gebruik te maken van aantal stellingen waarop deelnemers hun mening konden geven en konden sparren met de aanwezige vakgenoten.
Waarom is slechts 67% het eens met deze stelling?
Dat was de meest gehoorde feedback uit het publiek. Je brengt de datakwaliteit toch op order voor de business? Dan moet je dit toch aan ze kunnen uitleggen? Het antwoord van degenen die het niet eens waren met deze stelling, was dat je vaak de impact nog niet zo goed kunt uitleggen wanneer je datakwaliteit gaat aanpakken. Kasper Kisjes vult hierbij aan: Je wilt dat mensen in je bedrijf dingen anders gaan doen ten behoeve van de datakwaliteit. Dan moet je ze inderdaad wel kunnen uitleggen waarom ze dat doen. Maar dat neemt niet weg dat het soms lastig is om uit te leggen wat nou precies de impact is, vooral uitgedrukt in kosten. Een mogelijke oplossing is de betrokkenen te vragen hoeveel tijd ze exact besteden aan het op orde krijgen van data. Een voorbeeld hiervan is de tijd die je nodig hebt om iets moeten uitzoeken omdat de gegevens waarmee je moet werken niet kloppen. Verloren tijd als indicator is ook heel overtuigend.
Andere suggesties die voorbij kwamen om draagvlak en urgentie te creëren zijn:
- Wanneer het bedrijf groeit, wil de business vaak investeren in beter of efficiënter laten verlopen van processen. Er geldt dan ook voor datakwaliteit.
- Een andere indicator die goed werkt is klant’on’tevredenheid. Als datakwaliteit dit gaat oplossingen, krijg je buy-in.
- Zet de pijnpunten flink aan, bijvoorbeeld op basis van het jaarverslag van de organisatie. Relateer datakwaliteit aan wat er niet goed gaat en je hebt automatisch een business case.
- Maak het persoonlijk, benadruk het persoonlijk gewin of de persoonlijke pijn.
- Een tip uit de Non-Invasive Data Governance hoek: laat mensen opnoemen wat ze allemaal NIET kunnen doen door slechte data. Door dit te benoemen krijg je vanzelf de vraag
- Verzamel shockerende cases rondom datakwaliteit met zaken die grote gevolgen hebben als ze niet worden ondervangen. Zo laat je zien wat er gebeurt als je niets doet.
- Maak transparant waar de data, die mensen bijvoorbeeld moeten invoeren in een applicatie, voor dienen en waarom je die nodig hebt.
Slechts 33% geeft aan dat een bestuurlijke portefeuillehouder van data nodig is.
Opvallend, omdat er bij veel van de bedrijven van de aanwezigen toch in silo’s gewerkt wordt. Je hebt dan toch iemand nodig die over deze silo’s heen besluiten kan nemen? Steun van hogerhand is toch onontbeerlijk? Maar al snel wordt duidelijk in de discussie dat het hebben van benefithouders het meest belangrijk is. Dat zijn je pleitbezorgers en dat hoeven niet persé bestuurlijke portefeuillehouders te zijn. Kasper Kisjes vertelt dat ze bij Rijkswaterstaat zijn gestart met een team van enthousiastelingen die over de silo’s heen aan de slag konden. Ook wanneer je bottom-up aan de slag gaat, kun je ver komen. Belangrijk is wel dat je datakwaliteit niet als project ziet wat je opstart en ook weer afrondt. Datakwaliteit moet een structureel onderdeel worden van je organisatie. Je wilt tenslotte continu grip krijgen op datakwaliteit.
Data Quality geen verloren zaak…
Ondanks dat veel deelnemers herkennen dat het zeker voorkomt dat medewerkers zich alleen verantwoordelijk voelen voor ‘hun’ data, geloven ze toch dat het geen verloren zaak is. Ja, er moet wel centrale sturing zijn om te voorkomen dat er wordt gedacht in ‘mijn’ versus ‘zijn/haar’ data. De belangrijkste DO’s die voortkwamen uit dit discussiepunt, waren:
- Zorg voor transparantie: Het gemeenschappelijk belang van kwaliteit van data moet voor iedereen duidelijk zijn. Alleen dan krijg je mensen in beweging.
- Zorg dat je de verbinder bent tussen eigenaarschap en benefithouder. Wanneer je zorgt dat de belangen bij elkaar komen, krijg je de boel in beweging.
Toolselectie niet het juiste startpunt
De grote meerderheid was het erover eens dat het kiezen voor een datakwaliteitstool niet het juiste startpunt is voor het structureel aanpakken van datakwaliteit. Wel beaamde men de waarde van bijvoorbeeld een dashboard om inzichtelijk en vooral ook visueel te maken wat de issues zijn. Want gevoel en beleving zijn zeer belangrijk wanneer je mensen in beweging wilt krijgen. Kasper Kisjes geeft aan dat je eigenlijk moet starten met het in kaart brengen van issues. En deze issues zitten aan de vraagzijde. Zo krijg je duidelijk waar je het voor doet. Wanneer je de issues boven water hebt, kun je pas een goede toolselectie maken. Een goede tool heb je overigens wel nodig om het gehele datakwaliteitsproces te meten en monitoren. Alleen dan maak je datakwaliteit tot een structureel proces.
Wrap-up met DO’s en DON’Ts
Een groot gedeelte van de Data Quality problemen en obstakels die de deelnemers aan het begin van de sessie noemden, zijn in de presentaties en discussie geadresseerd. Daarbij zijn er door de deelnemers heel wat DO’s en DON’Ts gedeeld en opgehaald.
Afsluiting
Als afsluiting lichtte Ronald Kok nog toe dat niet alleen het succes maar ook de energie zit in de samenwerking. Wanneer je investeert in het bijeenbrengen van personen en belangen, dan heb je de eerste slag gewonnen. Een heel goed instrument daarvoor is het spel Datapoly. Dit is terloops ter sprake gekomen tijdens de diverse breaks.
Daarnaast gaf hij de tip dat de Self-Assessment Rijksoverheid een heel goed middel is om het bestuur mee te krijgen in het onderwerp, zo ook voor datakwaliteit. Het geeft duidelijk aan waar je staat op basis van IST en SOLL. Vaak kun je dan na een korte investering in tijd, ongeveer een kwartier om een Self-Assessment in te vullen, de discussie aanzwengelen. Wil je hier zelf mee aan de slag? Klik dan op deze link om het materiaal aan te vragen.
-
Gert Jan Kentie
- 12 september 2019
Geweldig
Comments are closed.




")



















Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Scamander
Bernhardstraat 1
3433 EL Nieuwegein
Algemeen: 030-6029000
KvK : 30 15 16 09, Utrecht
E-mail: info@scamander.com
Copyright Scamander 2024
Copyright Scamander 2024
Geweldig